

In this post, I’ll take you quickly through our motivations and the technical considerations that have shaped the starting direction of the audio/visual instrument framework for VR we’re developing.
Background
Our Experience in Audio/Visual Instrument Design
I’ve been developing synthesisers, audio analysis/visualisation tools and music performance interfaces for bang-on a decade, primarily using Max/MSP/Jitter. Prior to that, I had composed electronic music using pretty standard programs and interfaces for over a decade. While editing music with a mouse was fine, my performances were always limited to a bank of dials, sliders or some other uninteresting interface object. I did so grudgingly and out of lack for more expressive options. I’ve always longed to physically engage with the music I perform, using an interface that wasn’t confined to a bunch of boxes with flashing lights sitting on desk.
“How can we leverage XR’s immersion and gestural interaction to make a performance interface that takes creative audio/visual expression to a new level?”
So, for the better part of my adult life, I’ve been building new ways to enhance the creative possibilities available to musicians, and to make the act of music creation more accessible and intuitive. In 2011, I released Kinectar, a Kinect-controlled music controller tool. Shortly after, Brad, Stephen and I started Ethno Tekh and released Tekh Tonic, software to enable music performance using a Leap Motion to interact with a physics-enabled 3D environment.
Following 3 years of creating interactive installations, custom stage performances and various creative software tools, we took slightly different roads. I completed my honours and masters degrees, both focused on music interface design approaches for Virtual Reality. While Brad and Stephen built a successful company, EXP, that design and develop a range of interactive installations and XR experiences. Their projects include XR-based narrative driven experiences, creative experiences and virtual fire fighter training.
Inspiration and Conceptual Approach
We’ve now combined forces once again for an ambitious project to create an immersive creative sandbox. We envisage this as an audio/visual instrument that exists all around the user, played and explored as intuitively as you interact with the physical world. In this environment, 3D objects not only make sounds, they are made of sound. To quote one of my biggest academic inspirations of audio/visual instrument design, Golan Levin, we are on a mission to create a virtual world that provides “an inexhaustible, infinitely variable, dynamic ‘substance’ whose visual and aural dimensions are deeply plastic and commensurately malleable” (Levin, 2000).
During this project, we want to not only solve technical problems, but ask questions that help us contribute to a greater conceptual understanding of XR as a tool for creative expression. What does it feel like to be immersed inside a virtual instrument? How do we interact with it? What kinds of new artwork can be produced by it? And importantly, how can we leverage XR’s immersion and gestural interaction to make a performance interface that takes creative audio/visual expression to a new level?
We hope to expand the sonic potential of interactive experiences and provide a far deeper bond between sound and vision. While our primary motivation is founded from a lifelong interest in creative expression, we realise that this approach could provide useful technical and conceptual contributions in fields such as game development, VR experiences and education, both in VR or AR spaces.
With that out of the way, let’s take a look at some of the major technical considerations that has shaped our development process.
Technical Considerations
As mentioned in the previous post, we chose to make our audio engine using Unity3D’s OnAudioFilterRead call, allowing us to write directly into the audio buffer of any “audio source”. This is so we could have maximum flexibility in synthesis and effects design, keep the benefits of the Oculus Spatializer plugin, and have an extremely tight integration between the interaction environment and the sounds that it produces.
The Power of Granular Synthesis
As you can see by the video below, there is a huge variety in the sonic outputs that can be created by gesturally controlled granular synthesis. Because granular synthesis relies on the layering of large numbers of unique sonic events, parameter-rich, gesturally-controlled environments provide an excellent platform for manipulating sounds.
One of the most important features of granular synthesis is its ability to supply unique parameters to individual grains. This creates a huge level of sonic possibilities, as layered grains can have their own pitch, volume, duration, playhead position from the audio clip or any number of digital signal processing (DSP) effects like those mentioned earlier.
In traditional 2D synthesiser interfaces, parameters can be controlled globally using GUI objects. In this case, variation between each grain is typically created by a randomisation factor controlled by the user, but it is impossible to manually control thousands of grains. But by placing grains in a virtual environment, they can derive their parameter values from objects within the environment itself. This makes the scalable nature of granular synthesis, along with its diversity of sonic output, an excellent choice for our first instrument.
The Pros and Cons of Audio Synthesis in Unity3D
Games engines are fantastic for, well, making games. What isn’t common in any game engine (I’ve heard of), is native support for a comprehensive DSP solution with audio synthesis applications in mind. Unity3D provides basic audio functions such as audio sources (for audio sample playback), audio listeners (the “ears” to listen to the sources) and a mixer to host effects. It also has in-built 3D audio spatialisation and doppler effects, making it an excellent solution for VR experiences. Finally, mixer channels can be populated effects from a large array of classic DSP effects that are perfectly suited for straight-forward sonic environments like those required by typical games.
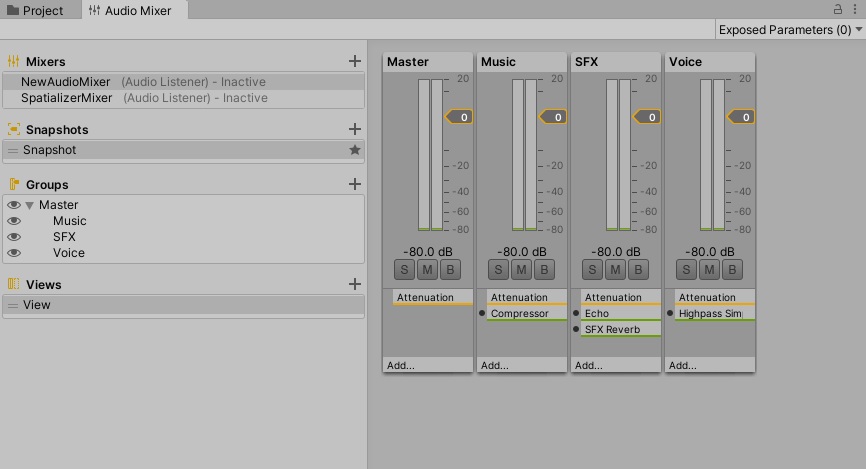
Despite all these convenient audio features in Unity3D, granular synthesis requires a far more (ahem…) granular approach to DSP. One of granular synthesis’ major draw-cards is that effects and modulations can be applied to individual grains, but the only way to do this with the default Unity3D paradigm is to send each grain to its very own mixer channel, effects chain, and parameter mapping scheme.
As you can see in the image of Unity3D’s audio mixer above, creating potentially thousands of channels and effect stacks using this method would be extremely unwieldy at best, and computationally irresponsible impossible at worst. To summarise, while Unity3D’s audio framework includes many useful features for traditional game development, it lacks the critical functionality required by an audio/visual performance tool that strays any distance beyond a couple of simple oscillator/filter combos.
Okay, So What Do We Need?
We need to build an entire DSP chain within C# that solves a bunch of challenges added by doing so within a game engine. 2D virtual synthesiser interfaces, generally populated with simple sliders, dials and buttons, require very little graphical processing. Frameworks focused on supporting audio tool development consider robust audio performance first and foremost. However, developing an integrated DSP framework inside a game engine needs a carefully designed system that efficiently processes lots of audio samples, very fast. Importantly, it needs to do so with strict timing and low latency, both at the mercy of fluctuating frame rates.
The bottom line is, we need to get creative if we want a DSP pipeline that’s efficient, flexible, and tightly integrated with the game environment.
Let’s put this simply, we want need to generate THOUSANDS of grains per second. We want to fill this virtual environment with dozens of interactive sound generators that can be gesturally controlled as audio/visual objects that exist within a fantastical world. But audio requires such a high rate of processing and rock-solid timing, keeping this system performant enough to produce acceptable results presents some challenges.
To provide some perspective, consider the fact that game engines are designed to process things once per visual frame (generally between 60 Hz and 144 Hz). Audio, on the other hand, runs at 44,100 Hz. So, let’s do some quick maths and assume the following:
- Audio sample rate of 44,100hz
- Grain duration of 200ms (44,100 x .2 = 8,820 samples per grain)
- Cadence of 5ms (200 grains per second)
Each second, this grain manager needs to copy 1,764,000 samples (8,820 x 200) to the grains. On top of that, each sample needs to have the windowing function and DSP effects applied before it’s finally sent to an audio source’s OnAudioFilterRead function call, each step having its own set of function calls or algorithms applied. While a single instance of this might do fine when developed using an intuitive design approach, one granular synthesiser isn’t enough for the environment we plan to create. And we certainly can’t keep it all in the main CPU thread. The bottom line is, we need to get creative if we want a DSP pipeline that’s efficient, flexible, and tightly integrated with the game environment.

Wrap Up
That’s enough for today. We’ve briefly looked at our motivations and potential of the project, chosen our audio synthesis approach, and identified a few technical considerations to have in mind before building a DSP chain in Unity3D.
In the next post, I’ll talk about the design approaches we’ve taken to build our granular synthesiser in Unity3D from a more technical perspective. I will outline the DSP chain we created in C#, and wrap up with the limitations and affordances of 3 distinct methods we’ve used to integrate a granular synthesiser within the Unity3D game environment.