
We have identified 3 different approaches to implement a deeply integrated granular synthesiser framework within the Unity3D game environment. Importantly, the chosen framework design will have a huge implication on performance and how immersive the sound-field can be, meaning we need to experiment with multiple approaches to see which best balances benefits and limitations.

How could we sonically activate an entire point cloud using granular synthesis? What are the challenges to do so in an interactive and sonically immersive way that doesn’t totally melt computers?
Virtual Space Sonification: Speakers and Emitters
Early in our development, we realised that developing a virtual environment, filled with interactive audio synthesis, would require a conceptual evolution beyond Unity3D’s existing audio source paradigm. The regular audio source component is attached to a GameObject that exists at a physical location, and contains both the audio clip to be played and a direct linkage to the Unity3D audio mixer channel it is assigned to.
This concept is fine when you’re simply playing back audio files. However, Unity3D becomes overwhelmed when it’s asked to perform audio synthesis with complex DSP effect chains on each audio source. Moreover, there is a limit of 255 voices in Unity3D, meaning that in a world with potentially thousands of sonic objects, these audio sources needed to be somehow grouped together.
This becomes possible in Unity3D by hi-jacking an audio source‘s OnAudioFilterRead function call. We simply create audio sources on objects without any audio clips attached. During runtime, we can use C# scripts to send audio data from anywhere else in the scene. We then overwrite the the audio source’s blank audio buffer with the audio from the external object using OnAudioFilterRead, therefore, spatialising sounds any way we wish.
How could we sonically activate an entire point cloud using granular synthesis? What are the challenges to do so in an interactive and sonically immersive way that doesn’t totally melt computers?
You could imagine Unity3D’s existing audio source paradigm as though you’re playing music through the speaker of a phone. The phone hosts the music playback AND the speaker through which you hear the music.
Now imagine a phone streaming music to a Bluetooth speaker. Here, the phone is an emitter of audio data that you hear from the location of the speaker. Moving the phone/emitter from one place to another has no affect on the sound’s spatial location. However, if you (the listener) or the speaker moves around the room, you will perceive a change in the sound’s location. So, the emitter‘s physical location has no bearing on how you spatially perceive the sound. Instead, sonic spatialisation is a function between the listener and speaker.
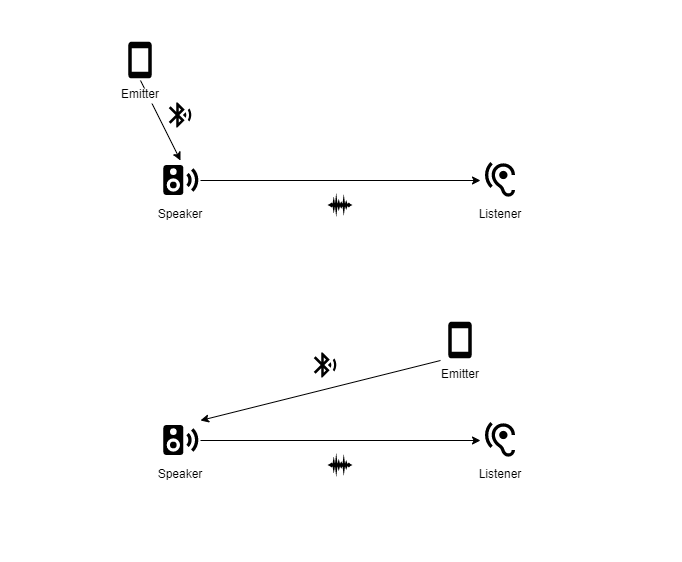
Here you can see this metaphor in action. Note how the emitter’s location plays no role in how the listener interprets the sound.
I’ll be using the metaphor of phones (emitters), Bluetooth speakers (speakers) and our ears (listeners) to help explain how we’ve built our granular synthesis integration within Unity3D. Assuming you’ve grasped the concept this far, I’ll be removing the Bluetooth and sound icons from the connections between emitters, speakers and listeners to keep things neat. Let’s dive in!
Approach 1: Single Emitter / Multiple Speakers
With this first approach, a single emitter sends out tiny slices of the original audio clip, called grains. Each grain is fed to a unique GameObject, called a speaker, that has both a RigidBody and an audio source component attached. We then overwrite the audio output buffer of the audio source component with the grain data sent from the emitter using the OnAudioFilterRead call. These sonic grains can now exist as physical objects within the 3D environment, enabling them to interact with the environment using Unity3D’s inbuilt physics engine. Great! Since each grain exists as an individual audio source, they have their own unique spatialisation, making it an extremely immersive sonic experience, as individual grains fly around your head.
…we send the grains to a set of speaker objects that spatially embed the sounds within the interactive 3D environment.
From a synthesis perspective, the emitter is basically a regular granular synthesiser. But instead of sending audio directly out of the user’s headphones, each grain is attached to a speaker object that spatially embed the sound within the interactive 3D environment.
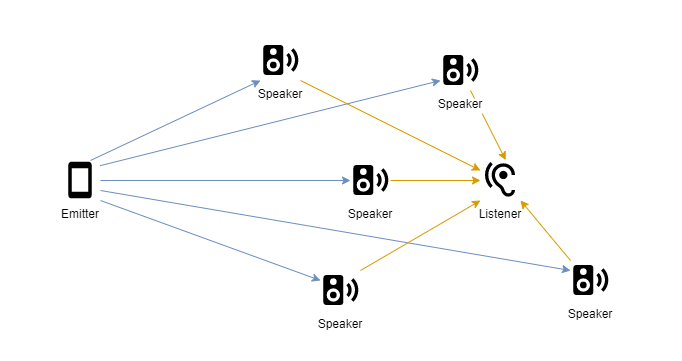
Unfortunately, this approach is limited in four critical ways:
- Performance: Each grain requires a GameObject, RigidBody component, DSP processing, OnAudioFilterRead (audio source component / voice) and are computed separately, creating a massive processing overhead.
- Clicks and Pops: In an attempt to conserve CPU, we tried toggling the speaker GameObjects off when their grain had finished. However, this caused clicks and pops in the audio output, which an issue that cannot be compromised on.
- Voice Limitation: There is a hard limit of 255 audio-voices in Unity3D. That means this approach can not technically produce the thousands of grains this project requires, since each grain would require its own voice.
- Single Emitter: Due to the inefficient use of computational resources in this approach, we were stuck using a single emitter. Using a single emitter doesn’t quite fit in with the paradigm we’re after, since we want to have grains being spawned from many locations, but also with many different audio clips feeding them. This would be a nightmare from a game world hierarchy management perspective.
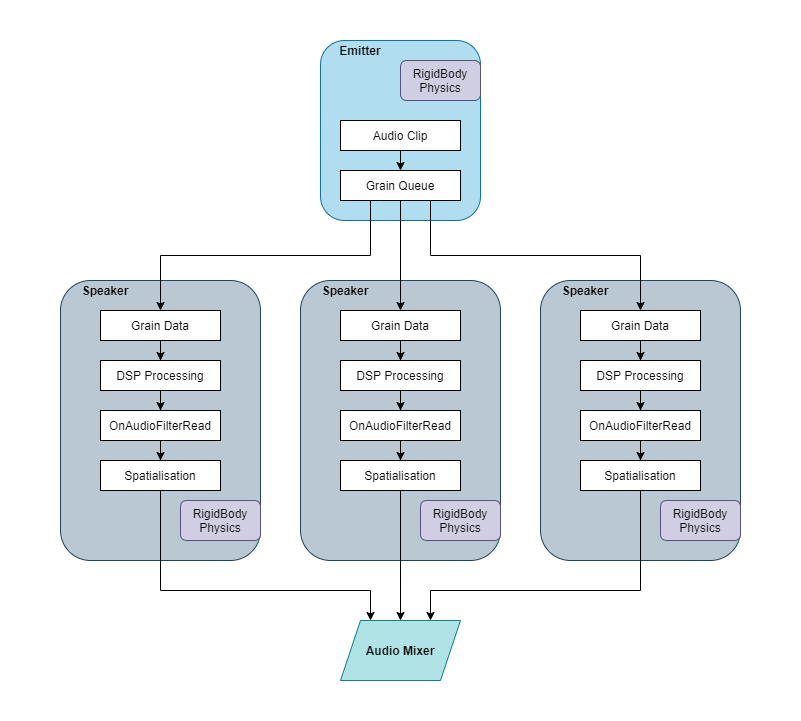
The GameObject and audio processing model for Approach 1.
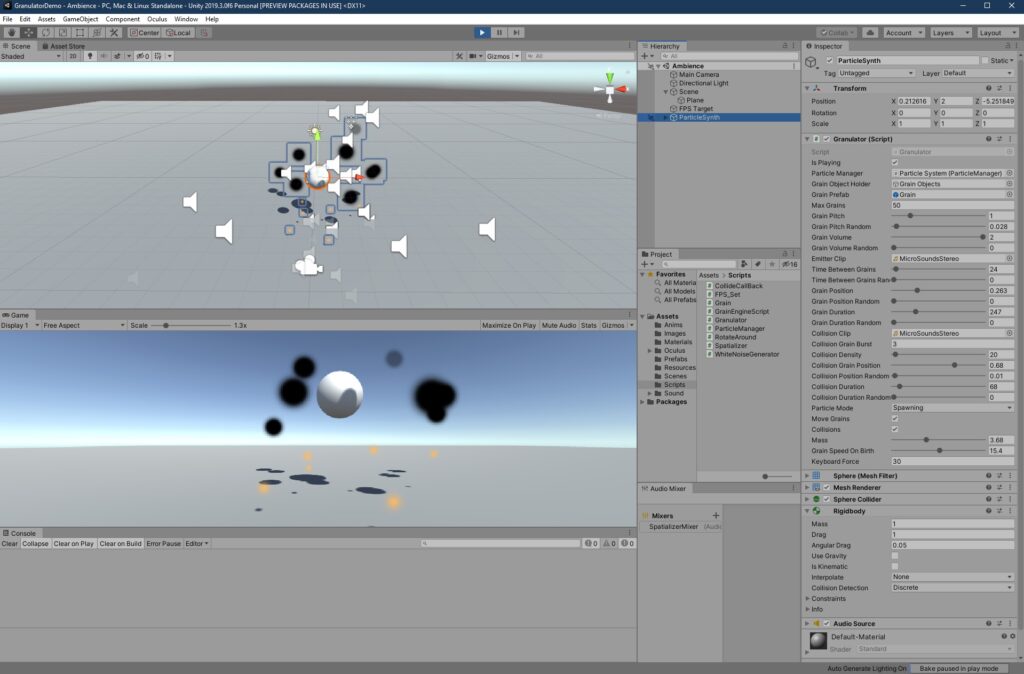
Note all the speaker icons in the top window that represent audio source GameObjects for each grain.
Approach 2: Multiple Emitters / Single Speaker
To eliminate the issues created by hosting each grain within their own GameObject audio source, we tried flipping the initial approach on its head. With the second approach, we consolidated to grain data from multiple emitters into a single speaker. The emitters can be attached to objects within the virtual environment and interactions with these objects can then drive the sonic parameters each emitter generates, and send their audio to the speaker. This lightens the CPU load significantly, since each grain no longer needs its own GameObject, only each emitter and the speaker. This stretches our phone / Bluetooth speaker metaphor (you’d rarely connect so many phones to a single speaker), but the concept is still the same.
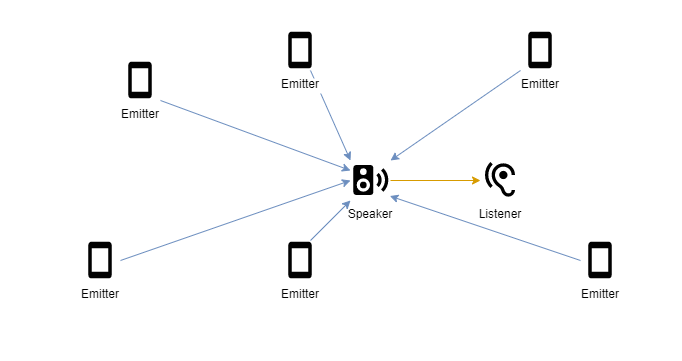
We can make things super efficient by sending all the audio data through a single speaker, but we lose a spatialisation in the process.
In this case, each emitter is sending out it’s own unique stream of granular synthesis grains. In our imagined environment, the user is surrounded in dozens of sonic objects, each with their own audio clip and effects, so having multiple emitters is critical.
Where this approach falls over, is that by using a single speaker to compile the grain data from ALL the emitters, all the sounds come from a single spatial location, meaning the objects that are interacted with are not spatialised as one would expect.
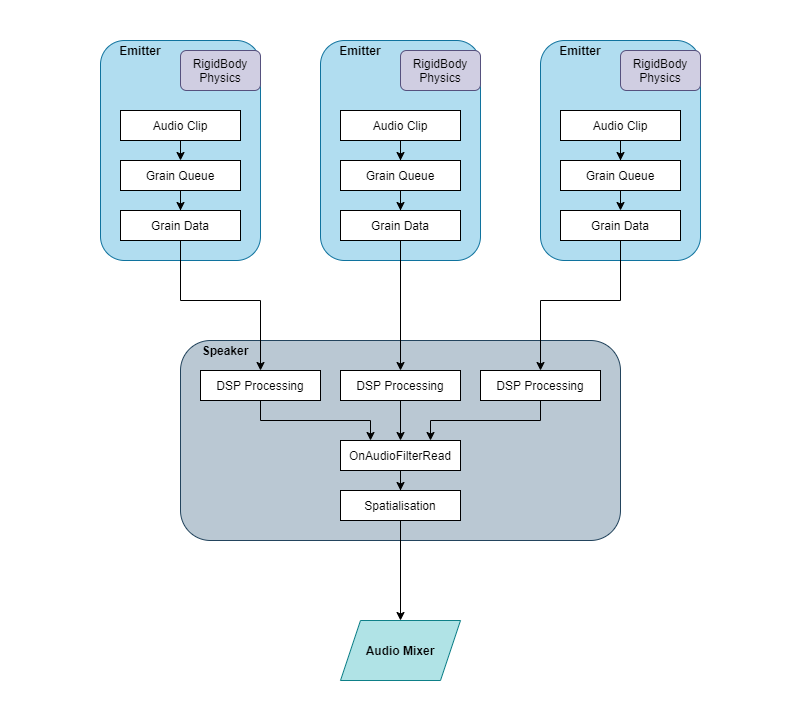
Note at the “spatialisation” function at the bottom of the “speaker” object. The audio data from ALL emitters (no matter where they are) will be spatialised from wherever the speaker is.
Approach 3: Dynamic Multiple Speakers and Emitters
Using this 3rd approach, we attempt to balance the benefits and limitations of both previous approaches. Here, many emitters can exist within the environment, and lay dormant until they are activated by being within the listener perimeter, centred on the user (listener).
The scene begins with no speakers and are added dynamically only as needed. When an emitter is activated, the emitter checks to see if a speaker exists within a speaker perimeter range. If not, a new speaker is placed at the location of the emitter. If there is an existing speaker nearby, the emitter attaches itself to the speaker and sends the grain data through it to the user. As the listener moves away from the emitters, their sound is faded out, until it is eventually detached from the speaker. When there are no more emitters attached to a speaker, the speaker is removed.
Going back to our phone / Bluetooth speaker metaphor, you could imagine this as having a number of Bluetooth speakers and phones scattered around a room. As phones are placed close enough to a speaker, it attaches to that speaker. But then imagine if those speakers and phones were smart enough to power on only when someone was close enough to hear it.
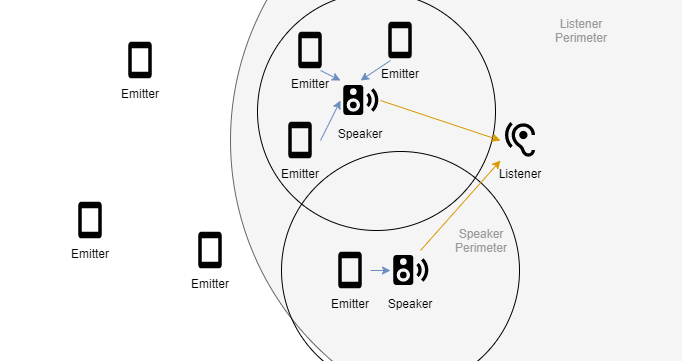
There is a large “listener perimeter” that activates the emitters. The emitters either latch on to a close speaker, or create a new one if there isn’t one in reach.
This approach drastically improves performance over Approach 1, since one of the largest overheads was the number of audio sources. It does so while maintaining the benefit of Approach 2, where many emitters can exist within a single environment.
Since the major savings in overhead are from emitters being able to share speakers, there is a compromise in terms of audio spatialisation. But this approach provides us with a number of variables to tweak so we can dynamically balance performance verses sonic immersion. Some sounds might require a greater level of localisation, so we could configure that emitter to accept speakers within a smaller range before creating a new one. Others might exist as more “background” sounds, where location is less important, so could be attached to a speaker form a greater distance far away from the user.
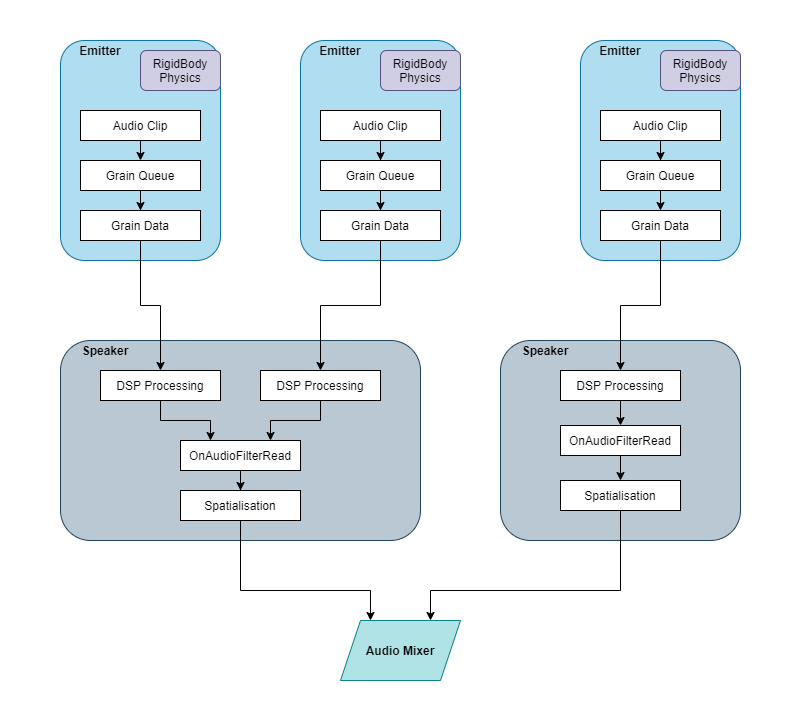
This framework allows a balance between spatialisation and performance, by sending close-together emitters through the same speaker.
We believe that this is the most versatile and efficient approach to embedded granular synthesisers with an immersive, dynamic and interactive audio/visual VR environment. If reasonably spaced within a large environment that a user could navigate through, there could be effectively countless emitters (granular synthesiser) that integrate tightly within the game world. If used in smaller, or even stationary VR environments, this approach could still be configured to appropriately balance performance and spatialisation.
Summary
The main takeaway here is that real-time audio spatialisation for immersive environments costs a lot of performance. To enable a virtual environment filled with real-time granular synthesis, a balance between spatialisation and performance must be made. Let’s break these approaches down with pros, cons and potential applications clearly identified.
| Framework | Pros | Cons | Applications |
|---|---|---|---|
| One Emitter, Many Speakers | Excellent audio spatialisation | Very inefficient | Single, highly spatialised interactive instrument |
| Many Emitters, One Speaker | Extremely efficient | Single point of spatialisation | Complex, single instrument with many sounds |
| Many Emitters and Speakers | Highly versatile and dynamically efficient | More complex to implement and imperfect spatialisation | Larger environments with high numbers of interactive sonic objects |
Worth noting, is that if the Many/Many approach is implemented properly, it can be configured to emulate any of the approaches with essentially equal efficiency.
Hopefully this post has started to untangle the ideas behind our work. While these are still just words and diagrams on a page, we’re in the process of putting together some example instruments and videos to help exemplify these somewhat abstract ideas as more tangible realisations.